August 1, 2022
PSAI ep.03

MinJun Choi

우선 spaCy를 알아보기 전에 짚고 넘어가야할 부분들이 있다.
용어 3개
loss function
- 머신러닝, 딥러닝 모델의 출력값과 사용자가 원하는 출력값의 오차를 의미
오차가 클수록 함수값이 증가함 - ex) 우리는 ‘java’를 skill로 분석하길 원했으나 모델이 이를 다른 label로 인식할 경우 그 차이가 함수값이고, 이와 같은 함수값이 최소화 되도록 하는 weight(가중치)와 bias(편향)을 찾는 것이 목표
- 오차정의 : MSE, RMSE, Binary Cross-entropy, etc.
Optimizer
- Optimizer는 주어진 데이터에 맞게 모델 파라미터를 최적화 시켜주는 역할을 함.
다시 말해서 loss function의 값들이 최대한 작아지도록 파라미터(w-weight, b-bias)들을 조정 - Optimizer 종류: gradient descent, Momentum, SGD, etc.
Gradient
- loss function은 n-차원에서 그래프로 나타낼 수 있는데, gradient는 그 공간에서 그려지는 그래프의 기울기를 나타냄.
- 대부분의 Optimizer들이 loss function의 gradient를 통해 최소 함수값을 찾는데, spaCy에서는 어떤 방식으로 loss를 줄이는 지는 알 수 없음.
spaCy의 Training 과정
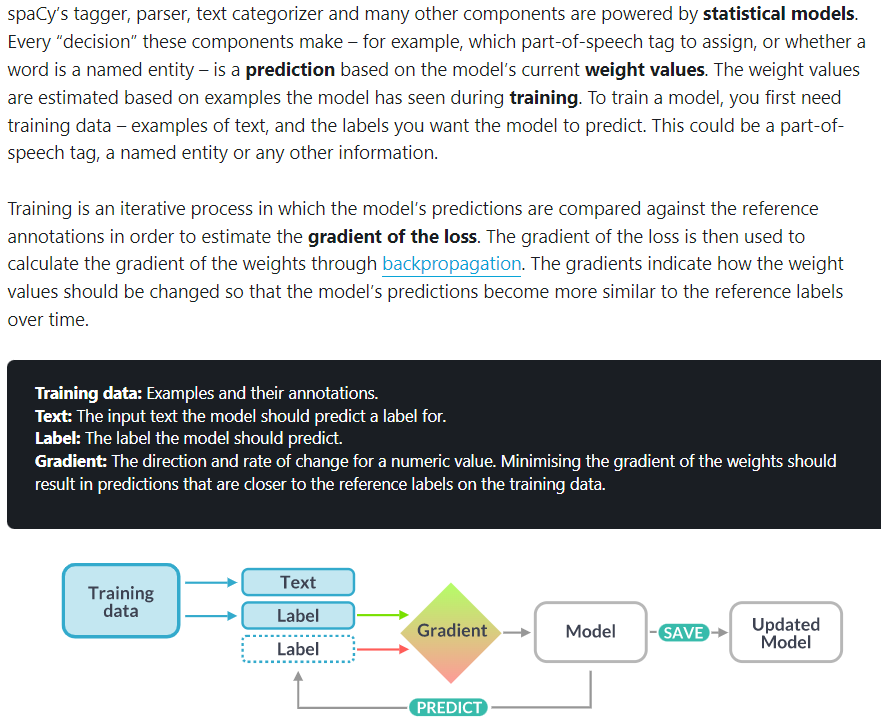 spaCy 공식 문서를 간단하게 정리
spaCy 공식 문서를 간단하게 정리
- spaCy는 이미 trained model이 있음.
- 사용자가 annotated data를 넣어주면 자체 model로 분석을 함.
- 사용자가 분석한 것과 자체 model이 분석한 차이를 비교. (loss 파악)
- gradient와 backpropagation을 통해 spaCy의 model에서 사용하는 weight와 bias를 조정
Backpropagation
- 출력값에 대한 입력값의 미분값을 출력층 layer에서부터 계산하여 chain rule에 따라 거꾸로 전파시키는 것
- 최종적으로, 출력층에서의 ourput 값에 대한 입력층에서의 미분값을 구할 수 있음.
왜 미분값을 구하냐
Optimizer들은 대부분 Gradient Descent에서 파생이 됐고,
이 방법에서 gradient (미분값)을 사용하여 loss가 최소가 되도록 하게끔 weight와 bias를 조정함.
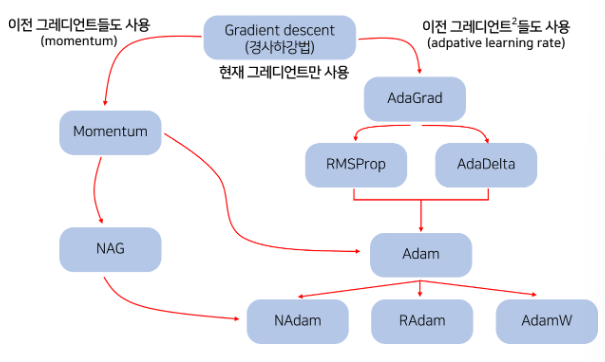
Gradient Descent
- Loss Optimizer 중에 하나
- graph의 gradient를 통해 Loss function의 최솟값을 유도할 수 있음
- weight와 bias를 조절함으로써 Loss를 줄이는 것을 목표
결론
이미 spaCy에서 만들어진 모델을 우리 입맛에 맞게 Update!